Andrej Karpathy | Building makemore Part 2: MLP @AndrejKarpathy | Uploaded 2 years ago | Updated 30 seconds ago
We implement a multilayer perceptron (MLP) character-level language model. In this video we also introduce many basics of machine learning (e.g. model training, learning rate tuning, hyperparameters, evaluation, train/dev/test splits, under/overfitting, etc.).
Links:
- makemore on github: github.com/karpathy/makemore
- jupyter notebook I built in this video: github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part2_mlp.ipynb
- collab notebook (new)!!!: colab.research.google.com/drive/1YIfmkftLrz6MPTOO9Vwqrop2Q5llHIGK?usp=sharing
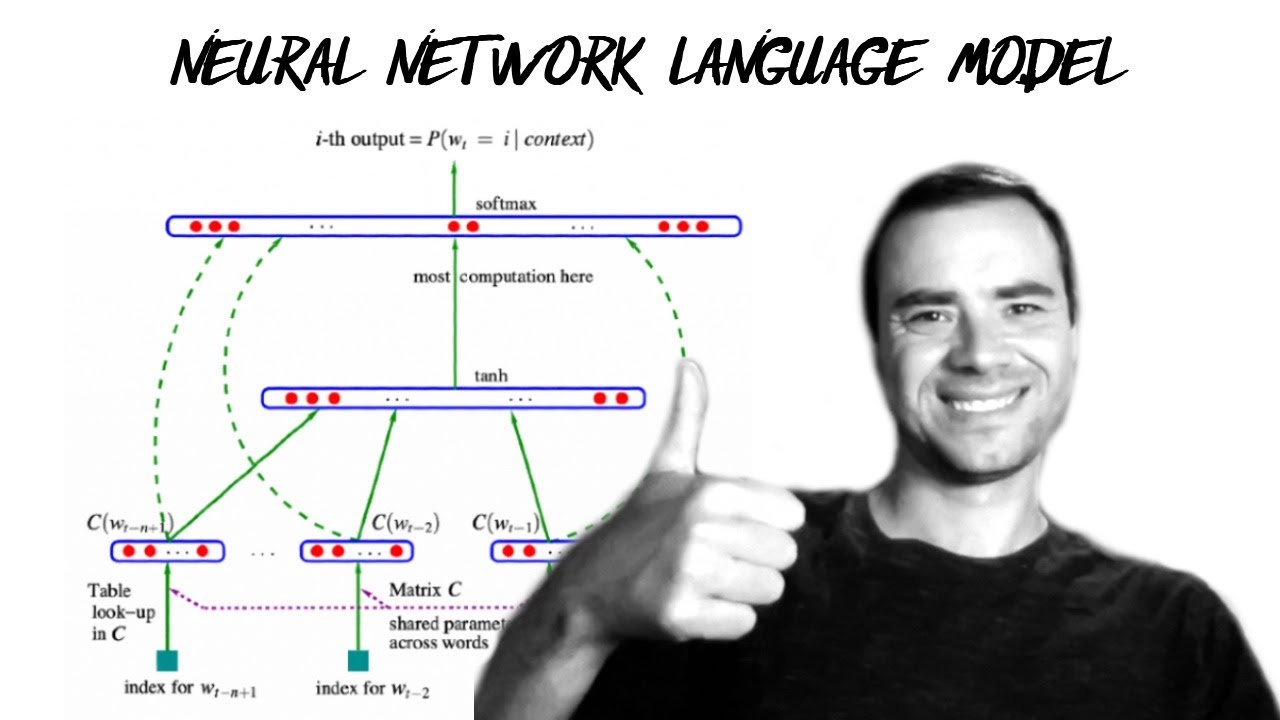
- Bengio et al. 2003 MLP language model paper (pdf): jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- my website: karpathy.ai
- my twitter: twitter.com/karpathy
- (new) Neural Networks: Zero to Hero series Discord channel: discord.gg/3zy8kqD9Cp , for people who'd like to chat more and go beyond youtube comments
Useful links:
- PyTorch internals ref http://blog.ezyang.com/2019/05/pytorch-internals
Exercises:
- E01: Tune the hyperparameters of the training to beat my best validation loss of 2.2
- E02: I was not careful with the intialization of the network in this video. (1) What is the loss you'd get if the predicted probabilities at initialization were perfectly uniform? What loss do we achieve? (2) Can you tune the initialization to get a starting loss that is much more similar to (1)?
- E03: Read the Bengio et al 2003 paper (link above), implement and try any idea from the paper. Did it work?
Chapters:
00:00:00 intro
00:01:48 Bengio et al. 2003 (MLP language model) paper walkthrough
00:09:03 (re-)building our training dataset
00:12:19 implementing the embedding lookup table
00:18:35 implementing the hidden layer + internals of torch.Tensor: storage, views
00:29:15 implementing the output layer
00:29:53 implementing the negative log likelihood loss
00:32:17 summary of the full network
00:32:49 introducing F.cross_entropy and why
00:37:56 implementing the training loop, overfitting one batch
00:41:25 training on the full dataset, minibatches
00:45:40 finding a good initial learning rate
00:53:20 splitting up the dataset into train/val/test splits and why
01:00:49 experiment: larger hidden layer
01:05:27 visualizing the character embeddings
01:07:16 experiment: larger embedding size
01:11:46 summary of our final code, conclusion
01:13:24 sampling from the model
01:14:55 google collab (new!!) notebook advertisement
We implement a multilayer perceptron (MLP) character-level language model. In this video we also introduce many basics of machine learning (e.g. model training, learning rate tuning, hyperparameters, evaluation, train/dev/test splits, under/overfitting, etc.).
Links:
- makemore on github: github.com/karpathy/makemore
- jupyter notebook I built in this video: github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part2_mlp.ipynb
- collab notebook (new)!!!: colab.research.google.com/drive/1YIfmkftLrz6MPTOO9Vwqrop2Q5llHIGK?usp=sharing
- Bengio et al. 2003 MLP language model paper (pdf): jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- my website: karpathy.ai
- my twitter: twitter.com/karpathy
- (new) Neural Networks: Zero to Hero series Discord channel: discord.gg/3zy8kqD9Cp , for people who'd like to chat more and go beyond youtube comments
Useful links:
- PyTorch internals ref http://blog.ezyang.com/2019/05/pytorch-internals
Exercises:
- E01: Tune the hyperparameters of the training to beat my best validation loss of 2.2
- E02: I was not careful with the intialization of the network in this video. (1) What is the loss you'd get if the predicted probabilities at initialization were perfectly uniform? What loss do we achieve? (2) Can you tune the initialization to get a starting loss that is much more similar to (1)?
- E03: Read the Bengio et al 2003 paper (link above), implement and try any idea from the paper. Did it work?
Chapters:
00:00:00 intro
00:01:48 Bengio et al. 2003 (MLP language model) paper walkthrough
00:09:03 (re-)building our training dataset
00:12:19 implementing the embedding lookup table
00:18:35 implementing the hidden layer + internals of torch.Tensor: storage, views
00:29:15 implementing the output layer
00:29:53 implementing the negative log likelihood loss
00:32:17 summary of the full network
00:32:49 introducing F.cross_entropy and why
00:37:56 implementing the training loop, overfitting one batch
00:41:25 training on the full dataset, minibatches
00:45:40 finding a good initial learning rate
00:53:20 splitting up the dataset into train/val/test splits and why
01:00:49 experiment: larger hidden layer
01:05:27 visualizing the character embeddings
01:07:16 experiment: larger embedding size
01:11:46 summary of our final code, conclusion
01:13:24 sampling from the model
01:14:55 google collab (new!!) notebook advertisement
 character-level language model. In this video we also introduce many basics of machine learning (e.g. model training, learning rate tuning, hyperparameters, evaluation, train/dev/test splits, under/overfitting, etc.).
Links:
- makemore on github: https://github.com/karpathy/makemore
- jupyter notebook I built in this video: https://github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part2_mlp.ipynb
- collab notebook (new)!!!: https://colab.research.google.com/drive/1YIfmkftLrz6MPTOO9Vwqrop2Q5llHIGK?usp=sharing
- Bengio et al. 2003 MLP language model paper (pdf): https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- (new) Neural Networks: Zero to Hero series Discord channel: https://discord.gg/3zy8kqD9Cp , for people whod like to chat more and go beyond youtube comments
Useful links:
- PyTorch internals ref http://blog.ezyang.com/2019/05/pytorch-internals/
Exercises:
- E01: Tune the hyperparameters of the training to beat my best validation loss of 2.2
- E02: I was not careful with the intialization of the network in this video. (1) What is the loss youd get if the predicted probabilities at initialization were perfectly uniform? What loss do we achieve? (2) Can you tune the initialization to get a starting loss that is much more similar to (1)?
- E03: Read the Bengio et al 2003 paper (link above), implement and try any idea from the paper. Did it work?
Chapters:
00:00:00 intro
00:01:48 Bengio et al. 2003 (MLP language model) paper walkthrough
00:09:03 (re-)building our training dataset
00:12:19 implementing the embedding lookup table
00:18:35 implementing the hidden layer + internals of torch.Tensor: storage, views
00:29:15 implementing the output layer
00:29:53 implementing the negative log likelihood loss
00:32:17 summary of the full network
00:32:49 introducing F.cross_entropy and why
00:37:56 implementing the training loop, overfitting one batch
00:41:25 training on the full dataset, minibatches
00:45:40 finding a good initial learning rate
00:53:20 splitting up the dataset into train/val/test splits and why
01:00:49 experiment: larger hidden layer
01:05:27 visualizing the character embeddings
01:07:16 experiment: larger embedding size
01:11:46 summary of our final code, conclusion
01:13:24 sampling from the model
01:14:55 google collab (new!!) notebook advertisement")

- (new) Neural Networks: Zero to Hero series Discord channel: https://discord.gg/3zy8kqD9Cp , for people whod like to chat more and go beyond youtube comments
Exercises:
you should now be able to complete the following google collab, good luck!:
https://colab.research.google.com/drive/1FPTx1RXtBfc4MaTkf7viZZD4U2F9gtKN?usp=sharing
Chapters:
00:00:00 intro
00:00:25 micrograd overview
00:08:08 derivative of a simple function with one input
00:14:12 derivative of a function with multiple inputs
00:19:09 starting the core Value object of micrograd and its visualization
00:32:10 manual backpropagation example #1: simple expression
00:51:10 preview of a single optimization step
00:52:52 manual backpropagation example #2: a neuron
01:09:02 implementing the backward function for each operation
01:17:32 implementing the backward function for a whole expression graph
01:22:28 fixing a backprop bug when one node is used multiple times
01:27:05 breaking up a tanh, exercising with more operations
01:39:31 doing the same thing but in PyTorch: comparison
01:43:55 building out a neural net library (multi-layer perceptron) in micrograd
01:51:04 creating a tiny dataset, writing the loss function
01:57:56 collecting all of the parameters of the neural net
02:01:12 doing gradient descent optimization manually, training the network
02:14:03 summary of what we learned, how to go towards modern neural nets
02:16:46 walkthrough of the full code of micrograd on github
02:21:10 real stuff: diving into PyTorch, finding their backward pass for tanh
02:24:39 conclusion
02:25:20 outtakes :)")
, following the paper Attention is All You Need and OpenAIs GPT-2 / GPT-3. We talk about connections to ChatGPT, which has taken the world by storm. We watch GitHub Copilot, itself a GPT, help us write a GPT (meta :D!) . I recommend people watch the earlier makemore videos to get comfortable with the autoregressive language modeling framework and basics of tensors and PyTorch nn, which we take for granted in this video.
Links:
- Google colab for the video: https://colab.research.google.com/drive/1JMLa53HDuA-i7ZBmqV7ZnA3c_fvtXnx-?usp=sharing
- GitHub repo for the video: https://github.com/karpathy/ng-video-lecture
- Playlist of the whole Zero to Hero series so far: https://www.youtube.com/watch?v=VMj-3S1tku0&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ
- nanoGPT repo: https://github.com/karpathy/nanoGPT
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- our Discord channel: https://discord.gg/3zy8kqD9Cp
Supplementary links:
- Attention is All You Need paper: https://arxiv.org/abs/1706.03762
- OpenAI GPT-3 paper: https://arxiv.org/abs/2005.14165
- OpenAI ChatGPT blog post: https://openai.com/blog/chatgpt/
- The GPU Im training the model on is from Lambda GPU Cloud, I think the best and easiest way to spin up an on-demand GPU instance in the cloud that you can ssh to: https://lambdalabs.com . If you prefer to work in notebooks, I think the easiest path today is Google Colab.
Suggested exercises:
- EX1: The n-dimensional tensor mastery challenge: Combine the `Head` and `MultiHeadAttention` into one class that processes all the heads in parallel, treating the heads as another batch dimension (answer is in nanoGPT).
- EX2: Train the GPT on your own dataset of choice! What other data could be fun to blabber on about? (A fun advanced suggestion if you like: train a GPT to do addition of two numbers, i.e. a+b=c. You may find it helpful to predict the digits of c in reverse order, as the typical addition algorithm (that youre hoping it learns) would proceed right to left too. You may want to modify the data loader to simply serve random problems and skip the generation of train.bin, val.bin. You may want to mask out the loss at the input positions of a+b that just specify the problem using y 1 in the targets (see CrossEntropyLoss ignore_index). Does your Transformer learn to add? Once you have this, swole doge project: build a calculator clone in GPT, for all of +-*/. Not an easy problem. You may need Chain of Thought traces.)
- EX3: Find a dataset that is very large, so large that you cant see a gap between train and val loss. Pretrain the transformer on this data, then initialize with that model and finetune it on tiny shakespeare with a smaller number of steps and lower learning rate. Can you obtain a lower validation loss by the use of pretraining?
- EX4: Read some transformer papers and implement one additional feature or change that people seem to use. Does it improve the performance of your GPT?
Chapters:
00:00:00 intro: ChatGPT, Transformers, nanoGPT, Shakespeare
baseline language modeling, code setup
00:07:52 reading and exploring the data
00:09:28 tokenization, train/val split
00:14:27 data loader: batches of chunks of data
00:22:11 simplest baseline: bigram language model, loss, generation
00:34:53 training the bigram model
00:38:00 port our code to a script
Building the self-attention
00:42:13 version 1: averaging past context with for loops, the weakest form of aggregation
00:47:11 the trick in self-attention: matrix multiply as weighted aggregation
00:51:54 version 2: using matrix multiply
00:54:42 version 3: adding softmax
00:58:26 minor code cleanup
01:00:18 positional encoding
01:02:00 THE CRUX OF THE VIDEO: version 4: self-attention
01:11:38 note 1: attention as communication
01:12:46 note 2: attention has no notion of space, operates over sets
01:13:40 note 3: there is no communication across batch dimension
01:14:14 note 4: encoder blocks vs. decoder blocks
01:15:39 note 5: attention vs. self-attention vs. cross-attention
01:16:56 note 6: scaled self-attention. why divide by sqrt(head_size)
Building the Transformer
01:19:11 inserting a single self-attention block to our network
01:21:59 multi-headed self-attention
01:24:25 feedforward layers of transformer block
01:26:48 residual connections
01:32:51 layernorm (and its relationship to our previous batchnorm)
01:37:49 scaling up the model! creating a few variables. adding dropout
Notes on Transformer
01:42:39 encoder vs. decoder vs. both (?) Transformers
01:46:22 super quick walkthrough of nanoGPT, batched multi-headed self-attention
01:48:53 back to ChatGPT, GPT-3, pretraining vs. finetuning, RLHF
01:54:32 conclusions
Corrections:
00:57:00 Oops tokens from the _future_ cannot communicate, not past. Sorry! :)
01:20:05 Oops I should be using the head_size for the normalization, not C")
 interpolate between randomly chosen noise vectors and render frames along the way.
This video was produced by one A100 GPU taking about 10 tabs and dreaming about the prompt overnight (~8 hours). While I slept and dreamt about other things.
Music: Stars by JVNA
Links:
- Stable diffusion: https://stability.ai/blog
- Code used to make this video: https://gist.github.com/karpathy/00103b0037c5aaea32fe1da1af553355
- My twitter: https://twitter.com/karpathy")

We reproduce the GPT-2 (124M) from scratch. This video covers the whole process: First we build the GPT-2 network, then we optimize its training to be really fast, then we set up the training run following the GPT-2 and GPT-3 paper and their hyperparameters, then we hit run, and come back the next morning to see our results, and enjoy some amusing model generations. Keep in mind that in some places this video builds on the knowledge from earlier videos in the Zero to Hero Playlist (see my channel). You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
Links:
- build-nanogpt GitHub repo, with all the changes in this video as individual commits: https://github.com/karpathy/build-nanogpt
- nanoGPT repo: https://github.com/karpathy/nanoGPT
- llm.c repo: https://github.com/karpathy/llm.c
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- our Discord channel: https://discord.gg/3zy8kqD9Cp
Supplementary links:
- Attention is All You Need paper: https://arxiv.org/abs/1706.03762
- OpenAI GPT-3 paper: https://arxiv.org/abs/2005.14165 - OpenAI GPT-2 paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf- The GPU Im training the model on is from Lambda GPU Cloud, I think the best and easiest way to spin up an on-demand GPU instance in the cloud that you can ssh to: https://lambdalabs.com
Chapters:
00:00:00 intro: Let’s reproduce GPT-2 (124M)
00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint
00:13:47 SECTION 1: implementing the GPT-2 nn.Module
00:28:08 loading the huggingface/GPT-2 parameters
00:31:00 implementing the forward pass to get logits
00:33:31 sampling init, prefix tokens, tokenization
00:37:02 sampling loop
00:41:47 sample, auto-detect the device
00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
00:52:53 cross entropy loss
00:56:42 optimization loop: overfit a single batch
01:02:00 data loader lite
01:06:14 parameter sharing wte and lm_head
01:13:47 model initialization: std 0.02, residual init
01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
01:39:38 float16, gradient scalers, bfloat16, 300ms
01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
02:00:18 flash attention, 96ms
02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping
02:21:06 learning rate scheduler: warmup + cosine decay
02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms
02:34:09 gradient accumulation
02:46:52 distributed data parallel (DDP)
03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU)
03:23:10 validation data split, validation loss, sampling revive
03:28:23 evaluation: HellaSwag, starting the run
03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro
03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA
03:59:39 summary, phew, build-nanogpt github repo
Corrections:
I will post all errata and followups to the build-nanogpt GitHub repo (link above)
SuperThanks:
I experimentally enabled them on my channel yesterday. Totally optional and only use if rich. All revenue goes to to supporting my work in AI + Education.")
 from the previous video and backpropagate through it manually without using PyTorch autograds loss.backward(): through the cross entropy loss, 2nd linear layer, tanh, batchnorm, 1st linear layer, and the embedding table. Along the way, we get a strong intuitive understanding about how gradients flow backwards through the compute graph and on the level of efficient Tensors, not just individual scalars like in micrograd. This helps build competence and intuition around how neural nets are optimized and sets you up to more confidently innovate on and debug modern neural networks.
!!!!!!!!!!!!
I recommend you work through the exercise yourself but work with it in tandem and whenever you are stuck unpause the video and see me give away the answer. This video is not super intended to be simply watched. The exercise is here:
https://colab.research.google.com/drive/1WV2oi2fh9XXyldh02wupFQX0wh5ZC-z-?usp=sharing
!!!!!!!!!!!!
Links:
- makemore on github: https://github.com/karpathy/makemore
- jupyter notebook I built in this video: https://github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part4_backprop.ipynb
- collab notebook: https://colab.research.google.com/drive/1WV2oi2fh9XXyldh02wupFQX0wh5ZC-z-?usp=sharing
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- our Discord channel: https://discord.gg/3zy8kqD9Cp
Supplementary links:
- Yes you should understand backprop: https://karpathy.medium.com/yes-you-should-understand-backprop-e2f06eab496b
- BatchNorm paper: https://arxiv.org/abs/1502.03167
- Bessel’s Correction: http://math.oxford.emory.edu/site/math117/besselCorrection/
- Bengio et al. 2003 MLP LM https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
Chapters:
00:00:00 intro: why you should care & fun history
00:07:26 starter code
00:13:01 exercise 1: backproping the atomic compute graph
01:05:17 brief digression: bessel’s correction in batchnorm
01:26:31 exercise 2: cross entropy loss backward pass
01:36:37 exercise 3: batch norm layer backward pass
01:50:02 exercise 4: putting it all together
01:54:24 outro")

Links
- Stable diffusion: https://stability.ai/blog
- Code used to make this video: https://gist.github.com/karpathy/00103b0037c5aaea32fe1da1af553355
- My twitter: https://twitter.com/karpathy")
 from DeepMind. In the WaveNet paper, the same hierarchical architecture is implemented more efficiently using causal dilated convolutions (not yet covered). Along the way we get a better sense of torch.nn and what it is and how it works under the hood, and what a typical deep learning development process looks like (a lot of reading of documentation, keeping track of multidimensional tensor shapes, moving between jupyter notebooks and repository code, ...).
Links:
- makemore on github: https://github.com/karpathy/makemore
- jupyter notebook I built in this video: https://github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part5_cnn1.ipynb
- collab notebook: https://colab.research.google.com/drive/1CXVEmCO_7r7WYZGb5qnjfyxTvQa13g5X?usp=sharing
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- our Discord channel: https://discord.gg/3zy8kqD9Cp
Supplementary links:
- WaveNet 2016 from DeepMind https://arxiv.org/abs/1609.03499
- Bengio et al. 2003 MLP LM https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
Chapters:
intro
00:00:00 intro
00:01:40 starter code walkthrough
00:06:56 let’s fix the learning rate plot
00:09:16 pytorchifying our code: layers, containers, torch.nn, fun bugs
implementing wavenet
00:17:11 overview: WaveNet
00:19:33 dataset bump the context size to 8
00:19:55 re-running baseline code on block_size 8
00:21:36 implementing WaveNet
00:37:41 training the WaveNet: first pass
00:38:50 fixing batchnorm1d bug
00:45:21 re-training WaveNet with bug fix
00:46:07 scaling up our WaveNet
conclusions
00:46:58 experimental harness
00:47:44 WaveNet but with “dilated causal convolutions”
00:51:34 torch.nn
00:52:28 the development process of building deep neural nets
00:54:17 going forward
00:55:26 improve on my loss! how far can we improve a WaveNet on this data?")

, where it translates between strings and tokens (text chunks). Tokenizers are a completely separate stage of the LLM pipeline: they have their own training sets, training algorithms (Byte Pair Encoding), and after training implement two fundamental functions: encode() from strings to tokens, and decode() back from tokens to strings. In this lecture we build from scratch the Tokenizer used in the GPT series from OpenAI. In the process, we will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. Well go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely.
Chapters:
00:00:00 intro: Tokenization, GPT-2 paper, tokenization-related issues
00:05:50 tokenization by example in a Web UI (tiktokenizer)
00:14:56 strings in Python, Unicode code points
00:18:15 Unicode byte encodings, ASCII, UTF-8, UTF-16, UTF-32
00:22:47 daydreaming: deleting tokenization
00:23:50 Byte Pair Encoding (BPE) algorithm walkthrough
00:27:02 starting the implementation
00:28:35 counting consecutive pairs, finding most common pair
00:30:36 merging the most common pair
00:34:58 training the tokenizer: adding the while loop, compression ratio
00:39:20 tokenizer/LLM diagram: it is a completely separate stage
00:42:47 decoding tokens to strings
00:48:21 encoding strings to tokens
00:57:36 regex patterns to force splits across categories
01:11:38 tiktoken library intro, differences between GPT-2/GPT-4 regex
01:14:59 GPT-2 encoder.py released by OpenAI walkthrough
01:18:26 special tokens, tiktoken handling of, GPT-2/GPT-4 differences
01:25:28 minbpe exercise time! write your own GPT-4 tokenizer
01:28:42 sentencepiece library intro, used to train Llama 2 vocabulary
01:43:27 how to set vocabulary set? revisiting gpt.py transformer
01:48:11 training new tokens, example of prompt compression
01:49:58 multimodal [image, video, audio] tokenization with vector quantization
01:51:41 revisiting and explaining the quirks of LLM tokenization
02:10:20 final recommendations
02:12:50 ??? :)
Exercises:
- Advised flow: reference this document and try to implement the steps before I give away the partial solutions in the video. The full solutions if youre getting stuck are in the minbpe code https://github.com/karpathy/minbpe/blob/master/exercise.md
Links:
- Google colab for the video: https://colab.research.google.com/drive/1y0KnCFZvGVf_odSfcNAws6kcDD7HsI0L?usp=sharing
- GitHub repo for the video: minBPE https://github.com/karpathy/minbpe
- Playlist of the whole Zero to Hero series so far: https://www.youtube.com/watch?v=VMj-3S1tku0&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ
- our Discord channel: https://discord.gg/3zy8kqD9Cp
- my Twitter: https://twitter.com/karpathy
Supplementary links:
- tiktokenizer https://tiktokenizer.vercel.app
- tiktoken from OpenAI: https://github.com/openai/tiktoken
- sentencepiece from Google https://github.com/google/sentencepiece")
![[1hr Talk] Intro to Large Language Models](https://i.ytimg.com/vi/zjkBMFhNj_g/hqdefault.jpg "[1hr Talk] Intro to Large Language Models
This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What they are, where they are headed, comparisons and analogies to present-day operating systems, and some of the security-related challenges of this new computing paradigm.
As of November 2023 (this field moves fast!).
Context: This video is based on the slides of a talk I gave recently at the AI Security Summit. The talk was not recorded but a lot of people came to me after and told me they liked it. Seeing as I had already put in one long weekend of work to make the slides, I decided to just tune them a bit, record this round 2 of the talk and upload it here on YouTube. Pardon the random background, thats my hotel room during the thanksgiving break.
- Slides as PDF: https://drive.google.com/file/d/1pxx_ZI7O-Nwl7ZLNk5hI3WzAsTLwvNU7/view?usp=share_link (42MB)
- Slides. as Keynote: https://drive.google.com/file/d/1FPUpFMiCkMRKPFjhi9MAhby68MHVqe8u/view?usp=share_link (140MB)
Few things I wish I said (Ill add items here as they come up):
- The dreams and hallucinations do not get fixed with finetuning. Finetuning just directs the dreams into helpful assistant dreams. Always be careful with what LLMs tell you, especially if they are telling you something from memory alone. That said, similar to a human, if the LLM used browsing or retrieval and the answer made its way into the working memory of its context window, you can trust the LLM a bit more to process that information into the final answer. But TLDR right now, do not trust what LLMs say or do. For example, in the tools section, Id always recommend double-checking the math/code the LLM did.
- How does the LLM use a tool like the browser? It emits special words, e.g. |BROWSER|. When the code above that is inferencing the LLM detects these words it captures the output that follows, sends it off to a tool, comes back with the result and continues the generation. How does the LLM know to emit these special words? Finetuning datasets teach it how and when to browse, by example. And/or the instructions for tool use can also be automatically placed in the context window (in the “system message”).
- You might also enjoy my 2015 blog post Unreasonable Effectiveness of Recurrent Neural Networks. The way we obtain base models today is pretty much identical on a high level, except the RNN is swapped for a Transformer. http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- What is in the run.c file? A bit more full-featured 1000-line version hre: https://github.com/karpathy/llama2.c/blob/master/run.c
Chapters:
Part 1: LLMs
00:00:00 Intro: Large Language Model (LLM) talk
00:00:20 LLM Inference
00:04:17 LLM Training
00:08:58 LLM dreams
00:11:22 How do they work?
00:14:14 Finetuning into an Assistant
00:17:52 Summary so far
00:21:05 Appendix: Comparisons, Labeling docs, RLHF, Synthetic data, Leaderboard
Part 2: Future of LLMs
00:25:43 LLM Scaling Laws
00:27:43 Tool Use (Browser, Calculator, Interpreter, DALL-E)
00:33:32 Multimodality (Vision, Audio)
00:35:00 Thinking, System 1/2
00:38:02 Self-improvement, LLM AlphaGo
00:40:45 LLM Customization, GPTs store
00:42:15 LLM OS
Part 3: LLM Security
00:45:43 LLM Security Intro
00:46:14 Jailbreaks
00:51:30 Prompt Injection
00:56:23 Data poisoning
00:58:37 LLM Security conclusions
End
00:59:23 Outro")