Oracle Developers | Automating Tasks Securely with RAG and a Choice of LLMs @oracledevs | Uploaded May 2024 | Updated October 2024, 6 hours ago.
In the effort to streamline repetitive tasks or automate them entirely, why not enlist the help of AI? Using a foundation model to automate repetitive tasks may sound appealing, but it may put confidential data at risk. Retrieval-augmented generation (RAG) is an alternative to fine-tuning, keeping inference data isolated from a model’s corpus.
We want to keep our inference data and model separated—but we also want a choice in which large language model (LLM) we use and a powerful GPU for efficiency. Imagine if you could do all of this with just one GPU!
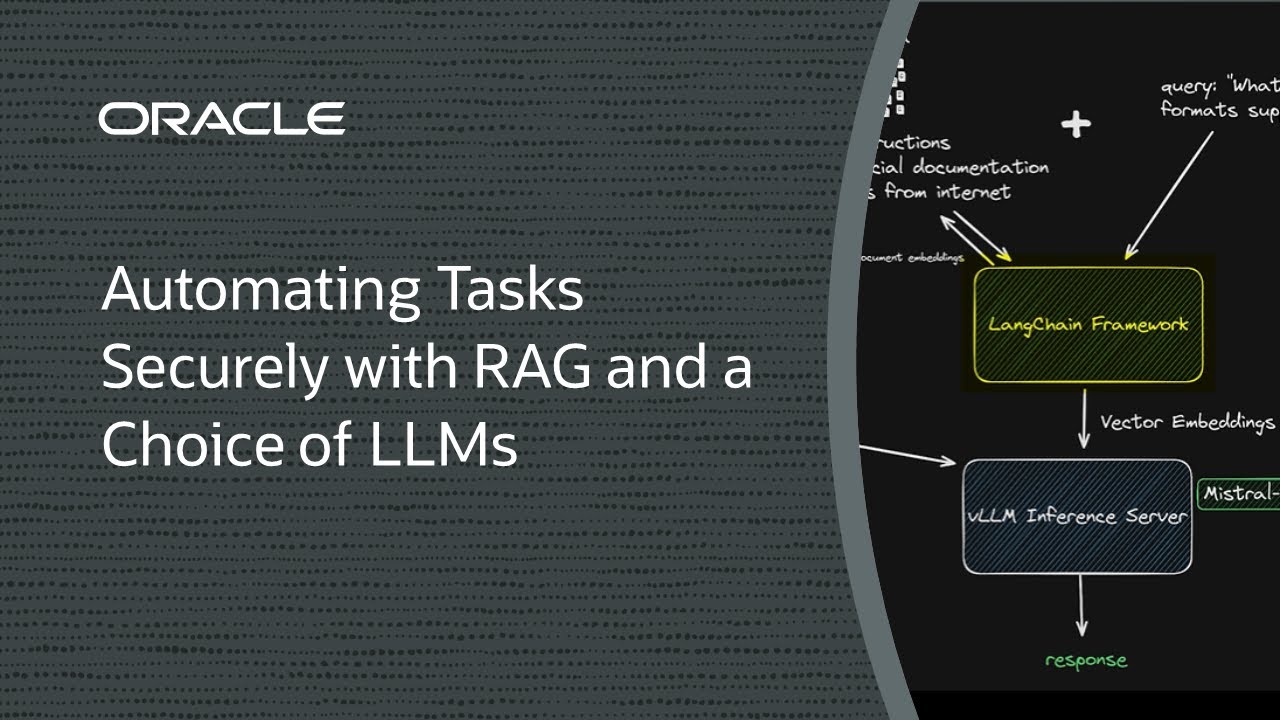
In this demo, we’ll show how to deploy a RAG solution using a single NVIDIA A10 GPU; an open source framework such as LangChain, LlamaIndex, Qdrant, or vLLM; and a light 7-billion-parameter LLM from Mistral AI. It’s an excellent balance of price and performance and keeps inference data separated while updating the data as needed.
In the effort to streamline repetitive tasks or automate them entirely, why not enlist the help of AI? Using a foundation model to automate repetitive tasks may sound appealing, but it may put confidential data at risk. Retrieval-augmented generation (RAG) is an alternative to fine-tuning, keeping inference data isolated from a model’s corpus.
We want to keep our inference data and model separated—but we also want a choice in which large language model (LLM) we use and a powerful GPU for efficiency. Imagine if you could do all of this with just one GPU!
In this demo, we’ll show how to deploy a RAG solution using a single NVIDIA A10 GPU; an open source framework such as LangChain, LlamaIndex, Qdrant, or vLLM; and a light 7-billion-parameter LLM from Mistral AI. It’s an excellent balance of price and performance and keeps inference data separated while updating the data as needed.
 is an alternative to fine-tuning, keeping inference data isolated from a model’s corpus.
We want to keep our inference data and model separated—but we also want a choice in which large language model (LLM) we use and a powerful GPU for efficiency. Imagine if you could do all of this with just one GPU!
In this demo, we’ll show how to deploy a RAG solution using a single NVIDIA A10 GPU; an open source framework such as LangChain, LlamaIndex, Qdrant, or vLLM; and a light 7-billion-parameter LLM from Mistral AI. It’s an excellent balance of price and performance and keeps inference data separated while updating the data as needed.")
 DNS - https://www.ateam-oracle.com/post/migrate-from-dyn-dns-to-oracle-cloud-infrastructure-oci-dns")
 provides both a logical air-gap and a physical air-gap to protect Oracle Database backups. In this session, we will focus on how the ZDLRA provides superior logical air-gap database protection over general purpose backup appliances.")

 proporcionen resultados más precisos y contextualmente relevantes con la generación de recuperación aumentada (RAG). En esta sesión puedes ver un demo de Vector Search en Oracle Database 23ai con APEX.")

 can step in to help create friendlier systems with more frequent updates based on new web pages.
In this demo, we’ll create a RAG model using OCI Generative AI, LlamaIndex, Qdrant vector database, and SentenceTransformerEmbeddings. This 21-line code will allow you to scrape web pages and use LlamaIndex for indexing, OCI Generative AI for question generation, and Qdrant for vector indexing.")


o Oracle Cloud VMware Solution: Security, predictability, and control make Oracle Cloud Infrastructure (OCI) the ideal platform for VMware. Rapidly transpose VMware estates to the cloud without changes to best practices or tools. (https://www.oracle.com/cloud/compute/vmware/?source=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&intcmp=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&elqCampaignId=369392&#GUID-850562D7-C268-479A-8627-EB6F4A5E707D)
o Multicloud: Oracle Cloud Infrastructure (OCI) offers a comprehensive set of multicloud solutions in the form of specialized deployments, database services, extensive monitoring capabilities, and strategic partnerships to fit your organizations needs. (https://www.oracle.com/cloud/multicloud/?source=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&intcmp=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&elqCampaignId=369392)
o Oracle Interconnect for Azure: provides organizations with a simple migration path to a multicloud environment that includes Oracle Database capabilities such as Oracle Exadata Database Service, Autonomous Database, and MySQL Heatwave. (https://www.oracle.com/cloud/azure/interconnect/?source=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&intcmp=:ow:lp:cpo::::RC_WWMK221208P00026:DMO400271824&elqCampaignId=369392)")

 Generative AI, which will summarize knowledge and create handy tips for employees that can be delivered on demand or on a schedule.")
 with the benefits of the relational model (no data duplication, referential integrity, use-case flexibility). One major aspect of JSON Relational Duality is its ability for proper data modeling. In this session we explain the concepts of JSON Relational Duality and why it is capable of solving complex and changing requirements, often found in enterprises where data is long lives and applications change over time.
We also showcase how the Hackolade Studio tool is best used to not only visually plan application collections but also generate JSON Relational Duality views with GUIs.")